Le site de liaison du nucléotide cyclique (CNBD : Cyclic nucleotide-binding domain) des protéines est un domaine d'environ 120 acides aminés. Comme son nom l'indique, il est retrouvé entre autres :
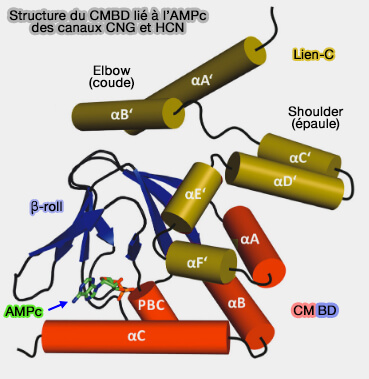
Lien-C et CMBD
(Figure : vetopsy.fr d'après Schünke et Stoldt)
dans les protéines kinases dépendantes de AMPc et de GMPc (cpkA et cpkG) ;
dans les récepteurs CNG (Cyclic Nucleotide-Gated channel) ;
Le rouleau β est entouré par l'hélice α N-terminale, une courte hélice α interne située entre les brins β6 et β7, désignée comme la cassette de liaison au phosphate (phosphate-binding-cassette : PBC) et deux hélices α (αB et αC) situé à l'extrémité C-terminale.
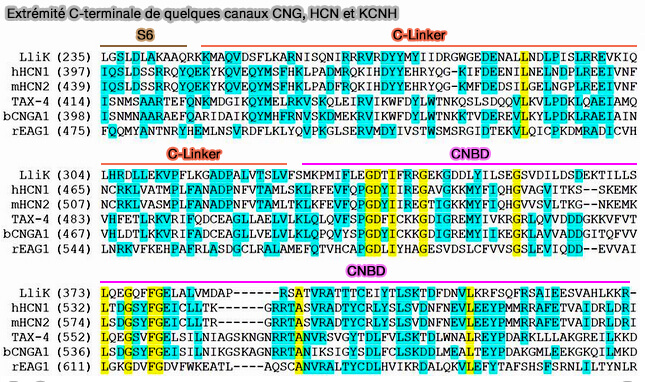
Extrémité C-terminale de quelques canaux CNG, HCN et KCNH
(Figure : James et coll)
Le nucléotide cyclique se lie à l'intérieur d'une cavité formée par certaines parties du rouleau β, l'hélice PBC et l'hélice αC.
La molécule d'AMPc est liée dans la conformation décalée (ou anti), telle que la fraction phosphoribose interagit avec les parties du rouleau β et l'hélice PBC par le biais d'interactions électrostatiques et de liaisons hydrogène.
Dans le canal HCN2, un résidu particulier R591 situé entre l'hélice PBC et β7, interagit directement avec l'oxygène exocylique chargé négativement du groupe phosphate. Ce résidu d'arginine ainsi que son interaction sont conservés et la mutation de ce résidu dans les canaux CNG et HCN diminue l'affinité pour les nucléotides cycliques.
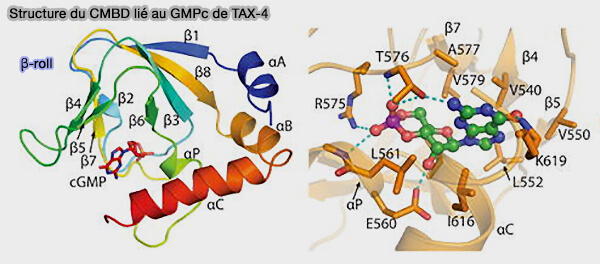
Dans les structures liées au GMPc, GMPc existe dans la configuration éclipsée (ou syn) qui facilite l'interaction de liaison hydrogène de l'atome N2 du cycle purique avec le résidu T592 situé dans le rouleau β. Il est rapporté que plusieurs résidus dans l'hélice αC (R632, R635, I636 et K638) augmentent la sélectivité des canaux HCN2 pour l'AMPc plutôt que pour le GMPc.
Structure du CMBD lié au GMPc de TAX-4
(Figure : Li et coll)
Les mutations des résidus situés dans αC dans les canaux HCN et CNG perturbent les interactions de cette hélice et altèrent la sensibilité des ligands et perturbent la fonction des canaux.
La liaison hydrogène avec l'amine N6 est formée par le squelette carbonyl oxygène du résidu R632. Ce résidu clé situé dans l'hélice αC a par la suite été signalé comme contrôlant l'efficacité par laquelle l'AMPc améliore l'ouverture des canaux. Le cycle purique interagit par des liaisons hydrogène avec des résidus supplémentaires situés à la fois dans le rouleau β et l'hélice αC. Les interactions de Van der Waals avec le cycle purique de l'AMPc sont formé par le résidu I636. Plusieurs interactions supplémentaires de van der Waals sont formées par les résidus R632 de l'hélice αC, et V564, M572 et L574 situés dans le rouleau β.
Les protéines kinases dépendantes de l'AMPc et de GMPc (cpkA et cpkG) contiennent deux copies en tandem du domaine de liaison de nucléotide cyclique.
Les cpkA sont composés de deux sous-unités différentes, une chaîne catalytique et une chaîne de régulation, qui contient les deux copies du domaine.
Les cpkG sont des enzymes à chaîne unique qui incluent les deux copies du domaine dans leur section N-terminale.